On a lark, I tried copying the Mountain Lion version of Mail.app (the /Applications/Mail.app bundle from a different machine running OS X 10.8.5) onto the machine with Mavericks. No dice:
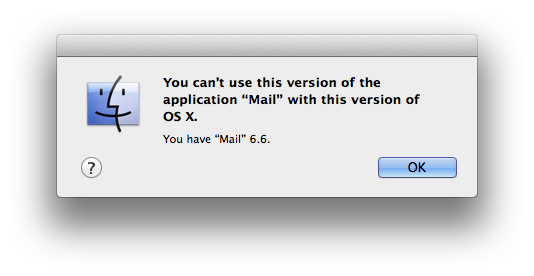
On a lark, I tried copying the Mountain Lion version of Mail.app (the /Applications/Mail.app bundle from a different machine running OS X 10.8.5) onto the machine with Mavericks. No dice:
Step 2. Wake said almost-2-year-old up in the middle of the night because you were going to a New Years party and didn’t have babysitting so you had him sleep in the guest room except he woke up and then saw all the cake and sweets and wanted to eat all the cake and then he had a sugar high and wanted to party.
Step 3. Lie awake in bed at 2 am as said almost-2-year-old says “Happy new year!” over and over and over and over.
Happy New Year, everybody!
]]>I see a lot of hate on the internet for Mail.app), but having tried many alternatives, I really like it1. Or did until Mavericks, which is the point of this post.
The Mavericks version of Mail.app made some big changes to how Mail.app talks to gimap, which I can only assume were to make things work better with gmail’s “labels” system and the idea that unlike with folders, one message can be filed with multiple labels. Because it worked fine before Mavericks, at the cost of perhaps syncing multiple copies of the same message. However, immediately after the Mavericks release, it was well documented that instead of making things better, they’d made them worse.
In fact, it was bad enough that Apple took the unusual step of releasing a Mail.app-Gmail specific update only a few days later.
In my experience, it made things a little better but far from good; even after the update
The 2nd and 3rd problems are annoying but cosmetic; the 1st problem, though, renders Mail.app entirely unusable. There doesn’t seem to be any workaround — I’ve tried switching folders many times, triggering Synchronize, triggering Rebuild Folder, logging out and logging back in, rebooting, quitting and restarting Mail, even deleting my entire mail cache folder and all accounts and re-adding the accounts and downloading all the mail again. Nothing helped.
Hopefully Apple will fix this soon (there are rumored to be further Mail.app/gmail bugfixes in an upcoming 10.9.1 update). As it is, it means I either can’t upgrade to Mavericks on the machine I actually care about2, or I need to find a different mail client.
So, in the past couple weeks I’ve spent some time dabbling in alternate mail clients. I haven’t found one I like.
For now, I’m sticking with OS X 10.8.
Notably, Mail.app is the only client I’ve ever used that makes IMAP feel perfectly natural, hiding all its design foibles. Other clients want to only download headers until I actually click on a message, or make me configure which folders get cached locally, or expose a difference between “delete” and “expunge”. Mail.app’s default settings just cache the whole IMAP mailstore in the background and make it feel like all the mail is local.↩
I upgraded some machines I can live without, to see how well Mavericks works. I wasn’t expecting any problems this big. But luckily I didn’t upgrade the laptop I do use every day, which I need for my job; unluckily that machine is the one that would benefit the most from Mavericks banner features: better power management and better multi-monitor support.↩
When you first turn on the new device, runs a fullscreen setup program that is not the normal iOS user experience starting at the home screen (Springboard). It wants to connect to a Wi-Fi network and then it asks you if you want to set it up as a new device or from a backup (and if the latter, whether to restore from iCloud or iTunes). If you elect to restore from an iCloud backup, it chews away for a few minutes restoring your user account, then reboots, and asks you a few further questions in the fullscreen setup program before jumping to the home screen.
As soon as the setup program exits and Springboard runs, normal background services and apps start launching and doing their thing, plus there’s still some first-use setup stuff to take care of, which means that all of the following try to happen simultaneously:
All of these happen in modal dialogs that pop to the foreground over the active app… or over one of the other aforementioned modal dialogs. This isn’t supposed to happen with modal dialogs. But it does, here, in the default out-of-box experience for pretty much any iOS device where the owner is upgrading from a previous one that was used for anything serious.
In fact, these password dialogs continue to pop up even when you’re in the middle of typing in an existing one (and if you manage to fill out and confirm one before another one takes its place, it seems like the previous ones may still be there with your previous partial input, or they may start empty when they reappear). The resultant focus stealing issues are worse than anything I’ve seen since the late 90s versions of Windows.
]]>This should be pretty straightforward — and it is, at other sites where I’ve set this up (Google, Facebook, Twitter). Apple’s setup process was a lot more complicated. Judging from the questions and admonishments during this setup process, Apple is a lot more worried than these others about people losing access to the “thing you have” and locking themselves out of their accounts. Which is a legitimate concern, but I think they can make the UI around this process a lot better.
The first place this went awry is the list of devices where they can deliver authentication codes. The AppleID website shows a list of known iOS devices (those enrolled in “Find my iPhone”), and allows you to select any/all of these, plus optionally one or more SMS-enabled phone numbers, to receive login verification codes. The problem is, all of these devices were listed as “offline”, even though at least 3 of them were actually online. I spent some time trying to figure out which parts of the description was clickable (spoiler: none, though there is one part that triggers an inaccurate explanatory popup if you mouse over it and hold still) before I eventually discovered a Refresh button at the very bottom of the list (far enough down I had to scroll to see it).
So beef #1: this page always loads stale information, and doesn’t show you correct information until you click a Refresh button that’s initially offscreen.
After selecting a couple notification methods here (which involves additional careful confirmation to make sure they actually work) and clicking Next, Apple showed me a “recovery key” with instructions to write it down or print it, but not to store it on any computer (and to enforce that, they make it impossible to copy it to the clipboard). OK guys, I get what you’re saying about the whole point being not exposing my keys to hackers, but if I write it on paper I’m going to lose it. Plus the computer I’m on doesn’t have a printer. I’m going to store this on my computer, thanks; I’ll just encrypt it. So I pull out my iPhone and open an encrypted note-taking program and type in this long alphanumeric code and check it carefully to make sure I transcribed it correctly. Then back to the computer and I click Next and it starts to ask me to retype the code, when suddenly… Session Timeout! Back to the very beginning. Time to start over (and this has taken about 10 minutes so far1).
So beef #2: aggressively short2 session timeouts are user-hostile, plus why not give me a chance to confirm I’m still there before just kicking me out of the session, plus the website was willing to let me sit there at the first “recovery key” page indefinitely long, and let me keep doing the work to copy down the useless recovery key3, and only when I click Next does it tell me the session had already expired.
This whole process would work a lot better if the 2 pages in question would dynamically update. AJAX in 2006 was pretty hot stuff. In late 2013, it’s table stakes.
OK, it won’t take me 10 minutes the second time, now that I know what I’m doing, notably with respect to the magic refresh button. But still, there was a lot of clicking done so far and a lot of clicking to repeat, and it’s pretty annoying.↩
The session timeout wasn’t actually so short that I couldn’t transcribe the recovery key, annoying as it is to type arbitrary hyphenated alphanumeric strings into the iOS keyboard. What actually happened was the AppleID website was slow and the page load between the “configure devices” and “recovery key” page took long enough I went to go do something else for a few minutes, then came back to the “recovery key” page, at which point the session had probably already expired before I even started dealing with transcribing the key.↩
Useless, because the second time through, the randomly generated recovery key was of course different.↩
And I’d been lucky enough to win an iPad 2, which turned into an Apple Store gift card for the value of an iPad 2, as a door prize recently.
And Apple was giving out Apple Store gift cards with most iPads as a Black Friday promotion that day.
So I added the new desired iPads to the shopping cart, configured them appropriately, clicked along until I got to the payment page, started looking for where to enter the code from my existing gift card… and this started a 15-minute odyssey of reading Apple help pages and becoming convinced the holiday cocktail I was sipping had addled my brain.
I mean, this is not supposed to be hard. But I couldn’t find anywhere to tell it I had this gift card.
First stop: Apple’s help page describing How to redeem Apple Store gift cards.
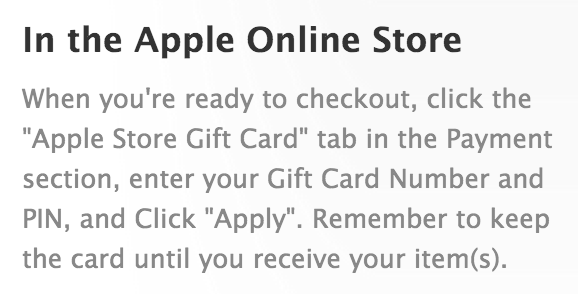
That sounds straightforward enough, but that’s funny, I don’t see any such option:
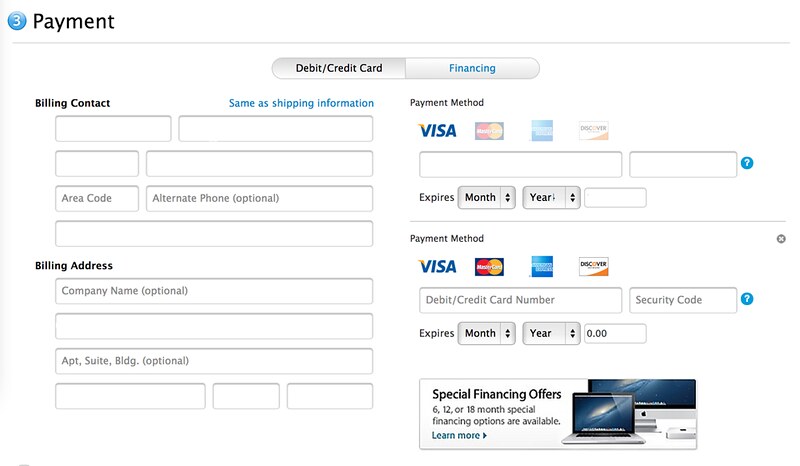
I delve farther into other more detailed help pages, to no avail.
Finally, feeling pretty stupid and blaming the cocktail, I clicked the “Live chat” help button. That popped up this window:
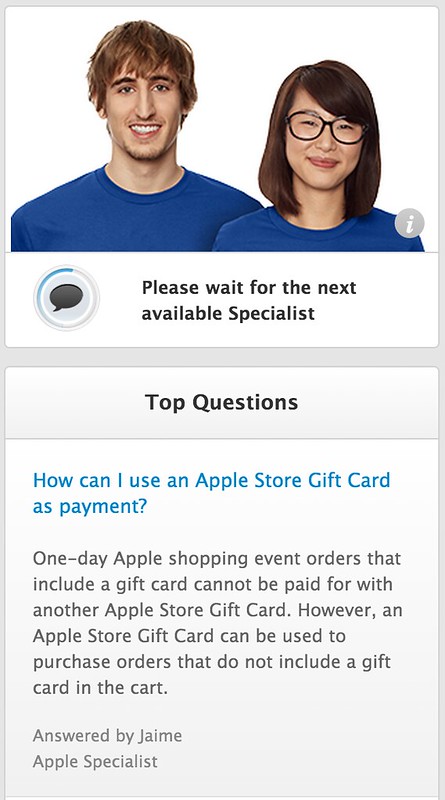
And there you have it. Q: “How do I use a Gift Card?” A: “Well, we don’t let you use gift cards on orders containing gift cards, and by the way, all orders today contain gift cards, so have fun trying to use a gift card. This was a sufficiently obvious question to make the #1 FAQ of the day, but we’ll only tell you this after you get frustrated enough to ask for help.”
This was a lot more confusing than it would have been if the “gift card” tab had remained present, which when selected would have been a perfect opportunity to say why this order wasn’t eligible for payment via gift card.
Pro tip for UI designers: making sometimes-applicable-but-not-now options disappear entirely is a lot less friendly than leaving room to explain why they don’t currently apply.
]]>My first stop was store.apple.com, because Apple’s website (compared to cell carrier websites) is simple1 and easy to use and doesn’t make you want to gouge your eyes out and doesn’t try to upsell you multiple useless accessories during the checkout process.
Then I hit this roadblock:
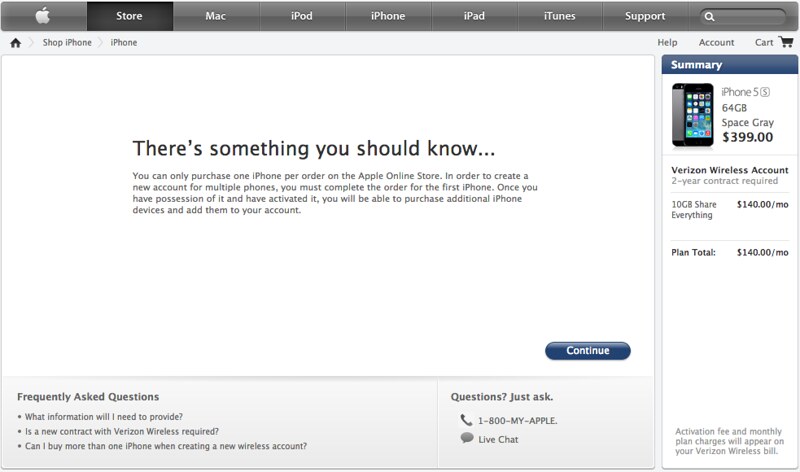
This was annoying because at the time (October) there was a 2 to 3 week waiting list for iPhone 5Ses. Presumably this 1-phone-per-order thing isn’t a problem in physical stores, but due to the backlog they weren’t actually stocking the phones in physical stores; you had to pre-order via the website. And the website’s solution was to order one phone, wait for it to arrive and activate it, then there’s enough of an account set up to add more phones to a family plan. But that would involve doubling the wait time, plus initially ordering a different plan than I want to end up on, and switching midmonth, which would probably involve who-knows-what kind of prorating madness. And then the phones wouldn’t all have the same contract date, which would haunt us 2 years from now. No thanks.
I don’t actually know what the reason is for this, that renders Apple unable to sell multiple phones to new customers. It doesn’t really make sense to me; that doesn’t seem like a strange thing to want.
Anyway, the solution was to head off to Verizon’s website, and just hold my tongue and avoid gouging my eyeballs out when confronted with their idea of website design and the multiple clicks per line to skip buying a bunch of accessories I didn’t need. But they were happy to let me sign up as a new customer and ship me 4 phones at once.
This is admittedly less true when buying a carrier-subsidized iPhone than anything else in the entire Apple Store. Everything else, you say you want to buy it and then you pay for it. A subsidized iPhone involves entering all sorts of billing information for your current contract plan or all sorts of loan-application-style information to set up a new contract plan. I can only imagine what kind of backend integration was necessary to get Apple’s store talking to all the cell networks’ billing systems.↩
Sprint has an email-to-SMS gateway that forwards messages sent to yournumber@messaging.sprintpcs.com. Verizon does the same thing using yournumber@vtext.com.
I was using this mechanism for a smattering of services that know how to send notifications by email but either don’t know how or charge extra for sending SMSes:
All of these alerts stopped happening when I switched providers, and I only noticed when I realized I wasn’t getting the alerts any more. Then I had to go back and try to remember everywhere I’d used that messaging.sprintpcs.com address (hint: this took a couple iterations).
A different case that ended up working out the same way is Twitter’s SMS integration. Here, they have real support for SMS (not cheaping out and using a per-carrier email forwarding gateway). But it still broke, with the same symptoms, when I switched carriers: over time, I realized I was no longer getting SMS notifications I used to get. I don’t know how Twitter’s SMS integration is implemented, and whether they do it themselves or use some service like Twilio; unlike a lot of sites I’ve seen that ask you for a phone number to SMS, they just ask for a phone number and not which carrier. Anyway, it broke and there was no obvious setting to change to fix it; I ended up deleting my phone number and re-adding it and that fixed things.
]]>Wireless: I switched our family plan from Sprint to Verizon, despairing that Sprint’s promised “Network Vision network upgrades will ever bear fruit here in the Bay Area. I’ve always like Sprint’s focus on less-confusing, lower-priced plans with an emphasis on unlimited data, but Network Vision has been in progress since 2010, their 3G network has been getting slower in my experience ever since then, and their LTE network is still on the horizon. Now that they’re finally converting Nextel’s lower-frequency spectrum for their own purposes, this could still turn out well, but after waiting 3 years for Network Vision to yield results, I was tired of holding my breath, and I sure wasn’t going to sign another 2 year contract under those conditions. Verizon is also The Man, but it turns out they basically don’t charge any more for a basically equivalent2 4-line family plan for 4 smartphones. So now we’re on Verizon’s LTE network, which ranges from awesome (20mbps down, 7mbps up) in downtown SF to barely passable (data barely trickles in each direction) around our house in the Mission District. Most of the time it works pretty well, though. Latencies on both Verizon’s LTE and 3G networks seem substantially better than Sprint’s 3G network (RTT on Verizon is usually around 70ms; with Sprint it was usually 200ms), which might also be a big factor in it feeling generally snappier for data. True, we had to give up unlimited data, but in practice (partly because it was so slow, partly just due to our natural usage patterns) we weren’t using all that much data on Sprint, and given the observed tradeoff, I actually think $10/GB is a fair price to pay for reliably fast data.
At work: A quick mention that at work, we’ve tried both Comcast and WebPass, another local-ish wireless provider with a focus on commercial installations. I like what WebPass is offering, because they sell symmetric connections and can scale up to quite high speeds. Unfortunately the plans that are cost-competitive with Comcast are quite a bit slower downstream, and reliability has not been all that good. The wireless link layer itself seems fine, but I’ve seen more than a few weird routing problems, and their tech support doesn’t reliably fix these quickly when reported or even call back with promised updates.
I could write a whole post on weird things you didn’t expect to deal with that crop up when you add multiple ISPs to your home network, like trying to keep the weird Xbox Live UDP protocol happy, or updating multiple dyndns addresses, or why it’s not easy to keep Shorewall happy when one link goes down. Maybe another day.↩
I found it interesting that (in the fall of 2013), Sprint’s mainstream plans all have unlimited data and messaging but still have metered voice minutes; Verizon’s mainstream plans all have unlimited voice and messaging but metered data.↩
When I went to order the one I wanted (the new retina-display version of the iPad Mini), I realized they didn’t have discounts on quite all the iPads. The “iPad Mini with Retina Display” is considered a different model and product than the normal “iPad Mini” (fair enough, I suppose) and there was no discount available.
My question: if Apple was discounting all other iPads including the equally-new and presumably hot-selling iPad Air, but not the Retina Mini, what does this indicate about the Retina Mini?
I have 2 theories:
The Retina Mini is in such high demand and/or short supply they have no need to discount it to sell it faster than they can make it.
The Retina Mini is already priced much closer to breakeven, and they can’t sell it significantly cheaper without losing money.
I have no idea which of these (if either) is true. I will note that, having ordered both an iPad Air and an iPad Mini with Retina Display that same day (identically configured, and given the $75 near-rebate on the Air, for nearly the same price), the Mini showed up a full week before the Air. That might put a hole in theory #1. Or it might just mean that the $75-off-an-Air promotion was such a huge hit that it created a huge backlog for the Air.
]]>As I noted before, a retina MBP (or MacBook Air) that doesn’t immediately wake when you open the lid is annoying not only because it slows you down, but because Apple’s removed all the battery indicator buttons, and there’s absolutely no sign of life from a powered off (or hibernating) machine until you press the power button.
So I woke it up with the power button on the builtin keyboard, and watched it boot to the preboot login screen associated with an encrypted boot drive1, and was further annoyed that at this screen it was still ignoring the external keyboard plugged into the Thunderbolt display. Having to use the builtin keyboard for a docked laptop is suboptimal. Anyway.
When it finished booting, I fired up pmset to ask it what’s going on, first on AC power:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
And then again2 on battery:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
As posted before, I’d previously changed standbydelay
to 43200 seconds on battery power, and disabled standby entirely on AC power. Apparently the 10.8.3
upgrade reverted the former change to Apple’s new default of 4200 seconds, though it left the latter
change alone.
Note that’s not quite consistent with my observation that my rMBP (bought in 2012 and shipped with
OS X 10.8) had standby enabled by default, while my previous MBP (bought in 2010 and shipped with
OS X 10.6 and subsequently upgraded to 10.7 and then 10.8) never had standby enabled at all.
The FileVault preboot login screen also annoys me because it’s got a pretty poor keyboard driver, and if I type my password at natural speed, it reproducibly detects one keystroke more than I intended to make. The same sequence of keystrokes is interpreted correctly by the real OS X keyboard stack. I reported this bug to Apple and they said they know and don’t care.↩
As an aside: anyone know how to get pmset to report the profile that’s not active? pmset -g reports all settings for battery when on batter, and all settings for charger/AC when plugged into AC, and I have found no way to get all settings for both profiles short of running pmset twice, and physically plugging or unplugging the power connector between runs. Note that the set mode of pmset takes an optional -a/-b/-c argument to specify whether to change the values for battery, charger, or both profiles, but those aren’t honored in conjunction with -g.↩
It took me a while to figure out what was wrong because there were actually 3 distinct problems. And as background, while it wasn’t a direct problem here, you should understand that footnotes are not a feature of the original Markdown syntax, but were added later by other dialects, mostly converging around PHP Markdown Extra, which is what Tumblr uses.
First: The post content generated in Markdown format from tumblr.rb, in its trip through nokogiri and html2text and maybe elsewhere, didn’t actually preserve the footnote declarations I’d originally given Tumblr. Even though I had written these posts in Markdown format, and the Markdown form of my posts is presumably preserved somewhere at Tumblr2, tumblr.rb instead downloads HTML and then reverse-converts it back to Markdown format. This conversion doesn’t preserve footnotes as Markdown footnotes; instead it leaves them as static HTML, and it renders the footnote bodies reasonably but the footnote links unreasonably.
So I had to go edit all the posts in which I used footnotes, and manually redo the footnote links using PHP Markdown Extra syntax.
Second: Having done that and told Jekyll to regenerate the blog, I found myself looking at a bunch of raw unconverted PHP Markdown Extra footnote tags. That’s because Jekyll’s markdown processing is done by RDiscount, and the version of RDiscount specified by Octopress’s Gemfile (1.6.8) does not support footnotes at all; footnotes using PHP Markdown Extra syntax were added as a feature of RDiscount 2.0.7, as an optional extension named footnotes.
So I had to edit the Gemfile to specify RDiscount 2.0.7, and edit _config.yml to enable the footnotes extension. These changes look like:
Gemfile:
1 2 | |
_config.yml:
1 2 3 | |
Third: Having done that and told Jekyll to regenerate the blog, some posts looked fine, but others had chunks of footnote definition content floating near the end of the post body but before the footnotes, and completely out of order. Some trial and error led me to deduce that RDiscount 2.0.7 does not actually honor the documented PHP Markdown Extra syntax, which allows you to hard-wrap the footnotes or even place the definition offset from the footnote number3; RDiscount is happy only if the footnote number and entire body are on one logical line with no hard line breaks. Since I’m doing all this posting from a colocated Linux VM on which I don’t run X, and thus use text editors in old-school terminal windows, I tend to hard-break my posts (and in fact, the posts I imported from Tumblr tended to be hard-wrapped at 76 columns by something somewhere along the write/post/import pipeline). RDiscount doesn’t play well with these hard breaks.
So I had to edit all the footnoted posts again to comply with RDiscount’s actual behavior.
Summary: you can get nice footnotes from Octopress/Jekyll if you
There’s still one more bug with footnotes on the index page, which is that Jekyll generates each page independently through RDiscount, which generates in-page links between the footnotes and their bodies, using the footnote number: for the first footnote, the forward link is #fn:1 and the backward link is #fnref:1. This works fine on individual pages, but on the index page the footnote numbers get reused and collide, so the in-page links don’t work there. Syeong Gan has a post with a deeper description of this problem, and a possible workaround.
Footnotes, Footnotify and Octopress has a pretty good argument in favor of footnotes, as well as a point-in-time description of how to get them to work in Octopress which I think is now outdated: he suggests switching from RDiscount to Kramdown; as mentioned above, RDiscount 2.0.7 added footnote support which mostly works. I tried Kramdown anyway and found RDiscount to do a slightly less bad job of honoring PHP Markdown Extra syntax than Kramdown does.↩
MarsEdit can edit posts already posted at Tumblr, even if not originally authored with MarsEdit, in their original format: if the post was written in Markdown, MarsEdit’s edit view sees Markdown. This might imply that there’s a better way for Jekyll’s tumblr.rb to use the Tumblr API to get the Markdown source, instead of the reverse-conversion it currently does.↩
See the PHP Markdown Extra documentation on footnotes, notably the part starting with “Footnotes can contain block-level elements”.↩
Octopress is basically a convenience framework around Jekyll, adding a nice-by-default theme and some convenience wrappers for starting new posts, invoking Jekyll to generate the site, and deploying the site. You could probably use Octopress quite happily without touching Jekyll directly, unless you want to import an existing blog; then you end up at Jekyll’s Blog Migrations tool, which has options for a number of popular blog engines, including Tumblr.
The instructions for setting up Octopress are pretty simple and well documented:
At this point, you’ve got a working Octopress installation and you could use its rake task-based interface to write and publish posts. However, if you want to migrate an existing blog, you have more setup steps which are also well documented:
gem install nokogiriruby -rubygems -e 'require "jekyll/migrators/tumblr"; Jekyll::Tumblr.process("http://www.your_blog_url.com", "md")' Note that this doesn’t require any account information or credentials, because the Tumblr API will provide enough information to do this anonymously. Heck, if you’re evil, you could convert someone else’s blog (don’t do that). On the topic of Tumblr reliability, I ran this step a few dozen times while I was figuring out how it works and fixing some bugs in tumblr.rb, and ~90% of the time, it downloaded my ~165 posts almost instantly, but palpably often, it would get stuck halfway as the Tumblr API stopped sending it network traffic. Oh well. Ctrl-C and restart if this happens to you.What neither the Jekyll nor Octopress documentation tells you is what happens next. Assuming you run all the above commands from the octopress directory: Octopress setup (the rake install step) created a directory called “source”, under which the (initially empty) “_posts” directory is where Jekyll will look for posts. Meanwhile, Jekyll’s tumblr.rb will create and populate a “_posts/tumblr” directory with your posts, and a “posts” directory with redirects from the old Tumblr-style post URLs to new Octopress-style URLs2,3. Neither the “_posts” nor “posts” directory spit out by tumblr.rb are under “source” where Jekyll will look for them. What this means is that without additional effort on your part, Jekyll as invoked by Octopress won’t see the files you just imported.
Again: your blog posts go in “octopress/source/_posts”. The Tumblr migrator will create “octopress/posts” and “octopress/_posts”. Just move these two directories under “octopress/source” once you’ve verified they look OK. (NB: the migrator actually dumped all its files under “octopress/_posts/tumblr”; it’s fine to leave them there, so they end up in “octopress/source/_posts/tumblr”; Octopress doesn’t seem to care about the organization of your files inside the source/_posts directory.)
Now, you can tell Octopress to generate the site: “rake generate”.
If you’re reading this at the right point of relative stability, lucky you; you win. I ran into several more issues, due to the fact that Jekyll and Octopress are prerelease open source software intended for an audience of hackers; some assembly definitely required:
system 'jekyll', with no arguments, and newer versions of Jekyll expect a build argument. Octopress will fix this when Jekyll actually releases a new version (which may have already happened between me finding this and posting this); it makes no sense to fix it sooner.This last list of foibles is probably all related to Jekyll being in the throes of the 1.0 release process and will probably be a historical footnote afterwards.
Many others have done this before; one post I found helpful was Goodbye Tumblr. Hello, Octopress Powered by Jekyll and Markdown!.↩
The redirects spit out by tumblr.rb are under “posts” because Tumblr URLs are of the form example.com/posts/12341234/post-title-slug; Octopress URLs are by default of the form example.com/blog/year/month/post-title-slug; tumblr.rb creates redirects from the former to the latter, without requiring any special interaction with the webserver, by just creating a file for each post, named for the Tumblr relative URL (in this case, posts/12341234/post-title-slug/index.html) containing a browser-side meta refresh redirect to the new URL.↩
I found the redirects created by tumblr.rb to be not quite enough. Tumblr indexes posts by number, then creates a nice search-engine-friendly SLUG such as post-title-slug, yielding a post URL like example.com/posts/12341234/post-title-slug. But actually, when receiving a request, Tumblr ignores everything after the number, and you could also load that post as example.com/posts/12341234/foobar, or just example.com/posts/12341234, and in fact the latter is the canonical URL used by Disqus. If you are running a webserver with rewrite rules, you might do well to redirect the entire URL namespace under posts/12341234 to the new URL, as Tumblr would have; I settled for copying posts/12341234/post-title-slug/index.html to posts/12341234/index.html for each post, so both number alone and number+SLUG will redirect correctly.↩
I’ve since realized that Tumblr is a bad match. Among things that I prioritize higher than Tumblr evidently does, reliability ranks high on the list1, as do control over site structure and appearance. Tumblr themes allow some control over appearance — and there are some very nice ones — but not the structure2.
Among things that they care about that I do not are their web posting interface, iOS native clients, a plethora of post types designed to be slightly quicker if you want to post audio/picture/video/quote content3, and a follower system4.
So. On to Octopress. I get a lot more control over site structure, a more usable form of control over visual layout, and I can host it somewhere reliable (github for now, myself if I want to, and I can move hosting providers without having to do any deeper conversion).
Reliability problems with Tumblr have been intermittent; sometimes it works fine, sometimes I get “the server returned no content” errors 10 times in a row before I can load a single page.↩
Tumblr’s main navigational construct is a list of all posts sorted in descending order by posting date. Individual posts get permalinks, and there’s a very slow-loading calendar view which gives some semblance of an overall table of contents, but there’s no really usable way to do monthly archives or next/previous links to stitch time back together.↩
All Tumblr posts have a URL, a title, and a body; what goes into the body can include really anything you can embed in a webpage, including audio and video. Presumably in an attempt to move beyond text-heavy blogging, in addition to letting you embed pictures/audio/video in a normal “text” post, Tumblr added these separate post types that special-case the body (the “link” post type makes the title into a navigable link; the “quote” type puts quotes around the body, etc). All of these are less general than the “text” type; they are also poorly represented in the API and, as I’ve found out, commensurately poorly handled by export tools. I dabbled in the special post types a few times, and am mostly sorry I did.↩
Readers are unlikely to be Tumblr users; that’s what RSS is for.↩
I wanted a Wi-Fi scan tool to show me a list of nearby wireless networks and strengths, so I could avoid interference from existing networks when placing and choosing a channel for a new access point, and verify the new access point is operating properly. A few years ago I did this with KisMAC, MacStumbler or iStumbler, but these utilities seem to have stopped working over time, either as a result of newer hardware or newer OSes.
Googling for new alternatives to these utilities, I found that Mountain Lion actually has this functionality built in. There’s a “Wi-Fi Diagnostics” app buried in /System/Library/CoreServices (where, annoyingly, Spotlight can’t find it and the Finder by default won’t show it); at launch it presents a very limited-looking wizard interface, but in the menubar the File:New command and command-N keyboard shortcut have been replaced by an unassuming “Network Utilities” command.
This brings up a “Network Utilities” window, not to be confused with /Applications/Utilities/Network Utility.app, with a bunch of really useful utilities (which look like a strict superset of the old Network Utility, have a more modern UI and additional functionality, and except for the “Wi-Fi Scan” tab, have no reason to be restricted to Wi-Fi networks).
I only wish this thing were easier to find; it should probably replace the old Network Utility app. I don’t remember seeing it mentioned in most what’s-new-and-why-to-upgrade articles about Mountain Lion. For me, it’s a pretty nice bonus to having upgraded and deserves wider mention.
The company claims the tablet is not only the “world’s thinnest 10.1-inch tablet” at 6.9 millimeters, but it’s apparently waterproof in up to three feet of water for 30 minutes.
The water resistance is a lot more notable to me than the thinness, in an industry obsessed with thin fragile things, given how many phones I’ve seen destroyed by water, and given how I put this on my wishlist for the iPhone 5 last fall. But phones see a lot more exposure to dangerous circumstances than tablets do, I wager, so I’d still like to see this feature make its way over to phones.
]]>That’s the dream, anyway. I’ve never owned or used a Windows laptop (or Linux laptop, for that matter) that pulled that off, and not for lack of trying. It was much truer of Apple laptops running Mac OS X, ever since their introduction in 2001. It remained one of my favorite things about more recent Macbooks, but I’ve found it getting less true over time, culminating in my 2012 “Macbook Pro with Retina Display” (henceforth rMBP), which seems to take like 30 seconds to wake from sleep, then sometimes crashes immediately as the crowning touch.
After getting frustrated enough by the slow wakeup time to get to the bottom of it, I think there are 3 pieces to the puzzle.
The rMBP (like Macbook Air models) has no external status lights. No charge level indicator on the battery like older models with removable batteries, no charge level indicator on the side of the unit like previous unibody Macbook Pro models, no power light that winks while asleep and glows while awake like all previous Macbook models. So when you open the lid, if it wakes up and is ready for use, great, but if not, you don’t know whether it’s powered off, has a dead battery, or is already trying to wake up and just taking its sweet time.
The default power-management plan is “Safe Sleep”, which means that when you close the lid the computer writes a suspend image to disk, then suspends to RAM1. Then wakeup is normally fast because RAM contents are still present, but if power is lost for any reason (battery dies, battery is removed on models where that’s possible, or the computer decides to power itself off to stop expending battery power to support the RAM), it can still resume from where you left it, just more slowly, by reading from disk. This last bit about deciding to power itself off is crucial; it’s controlled by a parameter known as standbydelay, and on this computer at least (rMBP running OS X 10.8) the default value of standbydelay was 4200 seconds, or 70 minutes, just over an hour. This means if you suspend the computer and wake it up again within 70 minutes, it will resume from RAM, but if you leave it asleep for more than 70 minutes, it will have powered off entirely, and will resume from disk. On my previous laptop (a 13” Macbook Pro from 2010, also now running OS X 10.8), standbydelay was not set at all, which I assume means it will try to keep RAM supplied with power until the battery dies. I don’t know the reason for the different defaults.
This rMBP has 16 gigabytes of RAM, more than any laptop I’ve owned in the past. Now, it also has a fast SSD, so I wouldn’t have thought it would take that much longer to resume from disk vs RAM (and in actual usage it shouldn’t have to save and restore all of it anyway) but it’s likely a factor: if it had to transfer the entire 16GB, even at 500 MB/sec that would be 32 seconds. It actually only needs to save/restore the active pages; say on average that’s 60% of memory and add a few seconds to get the hardware devices from cold boot to powered on, and you’re in the 20 second ballpark that is long enough to annoy me.
So boiled down: this machine feels slower to resume than previous ones because it’s suspending to disk, has a lot of memory to restore from disk, and doesn’t show any visible signs of progress while restoring from disk.
I changed the standbydelay value to 12 hours on battery (sudo pmset -b
standbydelay 43200) and disabled it entirely on AC power (sudo pmset -c
standby 0) and things seem much better now2.
Oh. And sleep reliability3? That’s even more important. When I first got the rMBP, it would kernel panic and show “Your computer must be restarted” when resuming from sleep once in a while, roughly once a month. That was intolerable; at a guess I disabled PowerNap; I don’t know whether it was the actual problem but I haven’t had reliability problems since.
So these are my current recommendations for power management on a rMBP or Macbook Air:
standbydelay value enough that you don’t notice the computer resuming from disk in normal useThe difference between suspend-to-disk and suspend-to-RAM is that suspend-to-RAM expends battery power to keep the contents of RAM alive, so wakeup is faster, while suspend-to-disk extends battery life at the expense of slower wakeup.↩
I didn’t realize the import of this at first, but Mac OS maintains separate sleep policies for battery and AC power, and pmset can set either one (-b for battery, -c for charger) or both (-a for both, which is also the default); so there are two standbydelay values. I have my computer set to never sleep on AC power, but I sleep it manually by closing the lid when I’m not using it. After having applied the longer standbydelay to battery, I was annoyed to find the computer slow to wake after leaving it asleep and charging for a while. Hence the second command to entirely disable the standby behavior on AC power.↩
When talking about sleep reliability, what’s actually important is the ability to wake back up reliably, just like when talking about backup reliability, what’s important is the ability to restore from backups. It’s the round trip that matters.↩
Of course, I went looking for ways around this. We had at our disposal a Mac laptop, two iPads and two iPhones. Mac OS X has built-in Internet connection sharing, but it operates only between separate network adapters: you can share an Ethernet-connected Internet connection over Wi-Fi, or vice versa, but you can’t share Wi-Fi over Wi-Fi1. There’s some reason to hope that this would be possible — it’s “just” a software problem2; Windows and Linux generally support multiple virtual Wi-Fi interfaces from the same physical device, as used by Connectify Hotspot for Windows or the multi-SSID feature in many Linux-based Wi-Fi access points — but this software feature doesn’t exist for Mac OS X.
So, no sharing Wi-Fi over Wi-Fi with my Mac laptop, unfortunately. But there’s another option that works without additional hardware; this is where the learning comes in. First new fact: you can share an Internet connection over Bluetooth. I’d thought this was only for sharing a cellular data connection from a phone to a computer (under the oxymoronic misnomer of “wireless tethering”), but it turns out to work in the other direction (known as “reverse tethering”). If you pair an iPhone or iPad with a Mac over Bluetooth, your Mac will grow a new network adapter called “Bluetooth PAN” (for Personal Area Network); you can then use the normal Sharing preference panel to enable Internet Sharing from Wi-Fi to Bluetooth PAN. Bingo.
(I can claim only partial success here, but it was good enough for me at the time. This technique works fine for iPads, but not iPhones. I don’t know why; nobody else seems to know why either.)
That got us past our trip, and I was happy to have a new tool for my cheap-connectivity-while-traveling toolbox. However, when we returned home, I had an unpleasant surprise, though it took me a while to connect the dots. My Mac laptop was getting really hot when I left it plugged in overnight to charge. I eventually realized this was because it wasn’t asleep, even with the lid closed (and with the lid closed, it generates more heat than it can comfortably dissipate, even at idle). This was frustrating because there are so many things that can keep a Mac from sleeping; this is where more learning comes in. Googling for ways to identify causes of Mac insomnia, I learned of the pmset -g log command, which I now highly recommend. It pointed me right at the culprit. Second new fact: Internet connection sharing prevents the Mac from sleeping while plugged in. (This is actually incredibly obvious in retrospect; it says so right in the Sharing panel: “Computers connected to AC power won’t sleep while Internet Sharing is turned on.” I hadn’t read that while enabling Internet Sharing because I thought I already knew how to use it; by the time it was causing problems, the problems were too disconnected from the cause.)
In summary: Internet connection sharing is useful, and the Bluetooth PAN variant is further useful, but don’t leave it on when you’re not using it.
Well, you can share Wi-Fi over Wi-Fi if you have multiple physical Wi-Fi interfaces. My laptop only has the one built-in Wi-Fi interface. It might be worth carrying a cheap additional USB Wi-Fi device for this reason. That would probably be the cheapest reliable solution to this problem.↩
At the physical layer, a single Wi-Fi radio can only be tuned to a single channel, but nothing stops it from participating in multiple SSIDs as long as they’re all on that channel.↩
pmset -g log.
I had a problem where my rMBP would sleep just fine on battery power but not when plugged into its charger. Even with the lid closed, and even if I explicitly poked the Sleep button first. This meant my chair got really warm if I left the computer sitting there plugged in to charge overnight. (NB: I did have the slider in energy saver preferences set to sleep:never for AC, but that should only affect sleep-after-idle, not lid-close or explicit sleep request.)
The command pmset -g log helped me learn that this state, where the computer is awake with the lid closed and no external display or keyboard is attached, is called DarkWake and that InternetSharing was the entity requesting that over sleep.
Now that I know about DarkWake, I’m curious what the relationship is between it and PowerNap. On this same rMBP, I disabled PowerNap because it would occasionally kernel panic when waking from sleep; I forget how I decided that was PowerNap but it hasn’t happened since disabling.
]]>I use the browser address bar (relying heavily on its autocomplete feature) to do most of my navigation directly from the keyboard. If I want my document files in Google Docs, I open a new browser tab from the keyboard shortcut, then type “docs” and by that time, autocomplete has already filled in docs.google.com1,2.
However, I have 3 different Google Accounts that I’m usually signed into: one standard personal account (ending in @gmail.com), one GAFYD3 account for my personal email4, and one GAFYD account for work. If I navigate to docs.google.com, Google automatically chooses one of the accounts to redirect to, and at different times on different computers I end up with a different (seemingly arbitrary) account selected, and if it wasn’t the right one, it’s 3 extra clicks in the account switcher to get to the right account.
What’s controlling its choice? It turns out it’s the order you sign into the accounts. If you look closely at the URLs, either by mousing over the links in the account switcher or by looking at the URL you end up at for gmail but not for docs5, you’ll see an “authuser” or “u” parameter which is a low-valued integer. It starts at 0 for the first account you sign into, and counts up from there as you sign into additional accounts.
If you navigate directly to docs.google.com (or mail.google.com, etc), you’ll get the account currently associated as authuser 0, which is the first account you signed into.
For the GAFYD case, Google lets you set up convenient forwarding addresses for domains you control, and I’ve used this to map mail.mydomain.foo and docs.mydomain.foo to redirect automatically to mail.google.com/a/mydomain.foo and docs.google.com/a/mydomain.foo. This means that for the two GAFYD domains, if I want the mail or docs view associated with that account, I go to docs.mydomain.foo, which in turn means that if I navigate to docs.google.com, I always want my personal account selected by default.
For me, the solution to get the behavior I wanted boils down to:
Thanks go to Ramesh for helping me figure this out.
Google has rebranded Google Docs as Google Drive, and docs.google.com redirects to drive.google.com. I haven’t retrained my fingers, so I always type “docs”, so I’ll keep using the old name. Both names work fine as described in this post.↩
(Everything in this post is true for other Google Accounts services like gmail, as well, but docs is the one I navigate directly to the most frequently, so I’ll stick with it for the example.)↩
Google Apps for Your Domain, back when that was a thing; since rebranded as Google Apps for Business once they removed the free option.↩
Why a separate gmail.com and personal GAFYD account? I’ve long used the same personal email address at a domain I control, predating Gmail. When Google created Gmail and started tacking many other services onto your Gmail account, becoming Google Accounts, I signed up with a gmail address but didn’t use it for email, just for Google Accounts. At some point I got tired of running my own email server and dealing with reliability and spam, so I decided to let Google host it via the then-free GAFYD. I could have just forwarded mail from the vanity address to the gmail address without setting up another mailbox, but it seemed simpler to keep them separate. That may have been a mistake.↩
The URLs vary by service, so this isn’t as obvious as it could be. Docs/Drive uses URLs like drive.google.com/?authuser=N in the account switcher, but for a GAFYD account, you actually end up at drive.google.com/a/mydomain.foo. Gmail uses URLs like mail.google.com/u/N, both in the account switcher and where you actually end up, though for a GAFYD account you can also navigate to mail.google.com/a/mydomain.foo (and you’ll be redirected to mail.google.com/u/N for the correct value of N if you’re already signed into that account, and to the login page if you’re not).↩